How we made our optical character recognition (OCR) code more accurate
Discover how we improved our optical character recognition (OCR) code for enhanced accuracy, efficiency, and real-world application.
What is optical character recognition?
Optical Character Recognition technology, OCR for short, is the recognition of printed or handwritten characters from digital images or scanned documents and their conversion into machine-readable text.
This technology has revolutionized the way documents are processed and managed, making it possible to extract information from paper-based documents and convert it into digital formats that can be easily searched, edited, and analyzed.
OCR systems use sophisticated algorithms to analyze the shape, size, and location of characters in an image, and then match them to a database of known characters to determine the text they represent.
The accuracy of OCR software has improved significantly in recent years due to advances in machine learning and artificial intelligence.
OCR code is widely used in various applications, such as document scanning and archiving, automated data entry, and processing forms.
It has also enabled the development of text-to-speech technology, which converts printed text into spoken words for people with visual impairments.
Optical character recognition at Pieces
For the past year, I’ve been a member of a team of machine learning engineers at Pieces for Developers working to develop an optical character recognition engine specifically for code.
Our optical character recognition software at Pieces uses Tesseract as its main OCR engine.
Tesseract performs an OCR layout analysis and then uses an LSTM trained on text-image pairs to predict the characters in the image.
It is currently one of the best free OCR tools and supports over 100 languages, but is not particularly fine-tuned to code. To make it really shine for code snippets, we added specific pre- and post-processing steps to our recognition pipeline.
Standardized inputs through image pre-processing
To best support software engineers when they want to transcribe code from images, we fine-tuned our pre-processing pipeline to screenshots of code in IDEs, terminals and online resources like YouTube videos and blog posts.
Since programming environments can be in light or dark mode, both modes should yield good results.
Additionally, we wanted to support images with gradients or noisy backgrounds, as might be found in YouTube programming tutorials or retro websites, as well as images with low resolution, for example from being compressed from uploading or sending a screenshot.
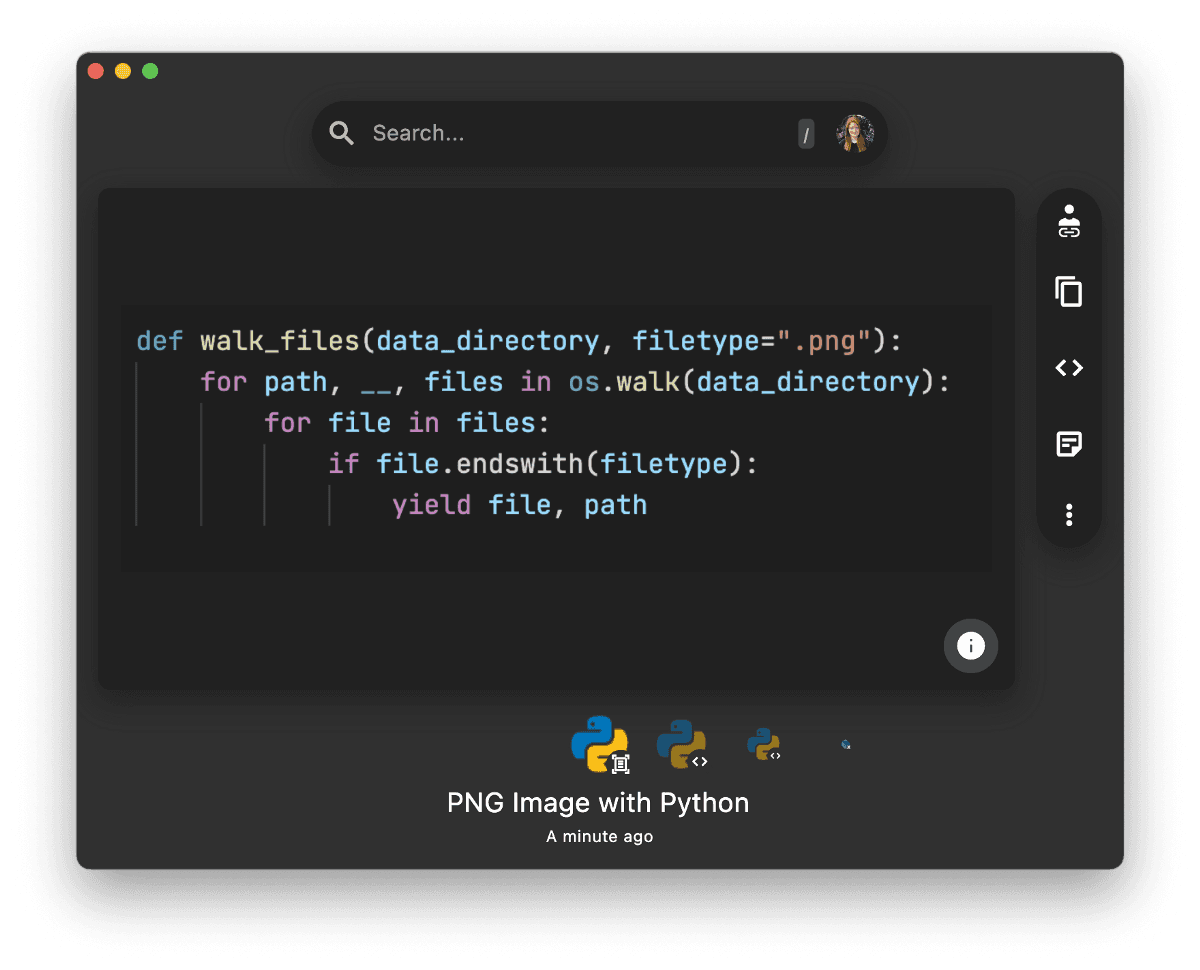
Since Tesseract's character recognition in image processing works best on binarized, light-mode images, we needed to invert dark-mode images in pre-processing.
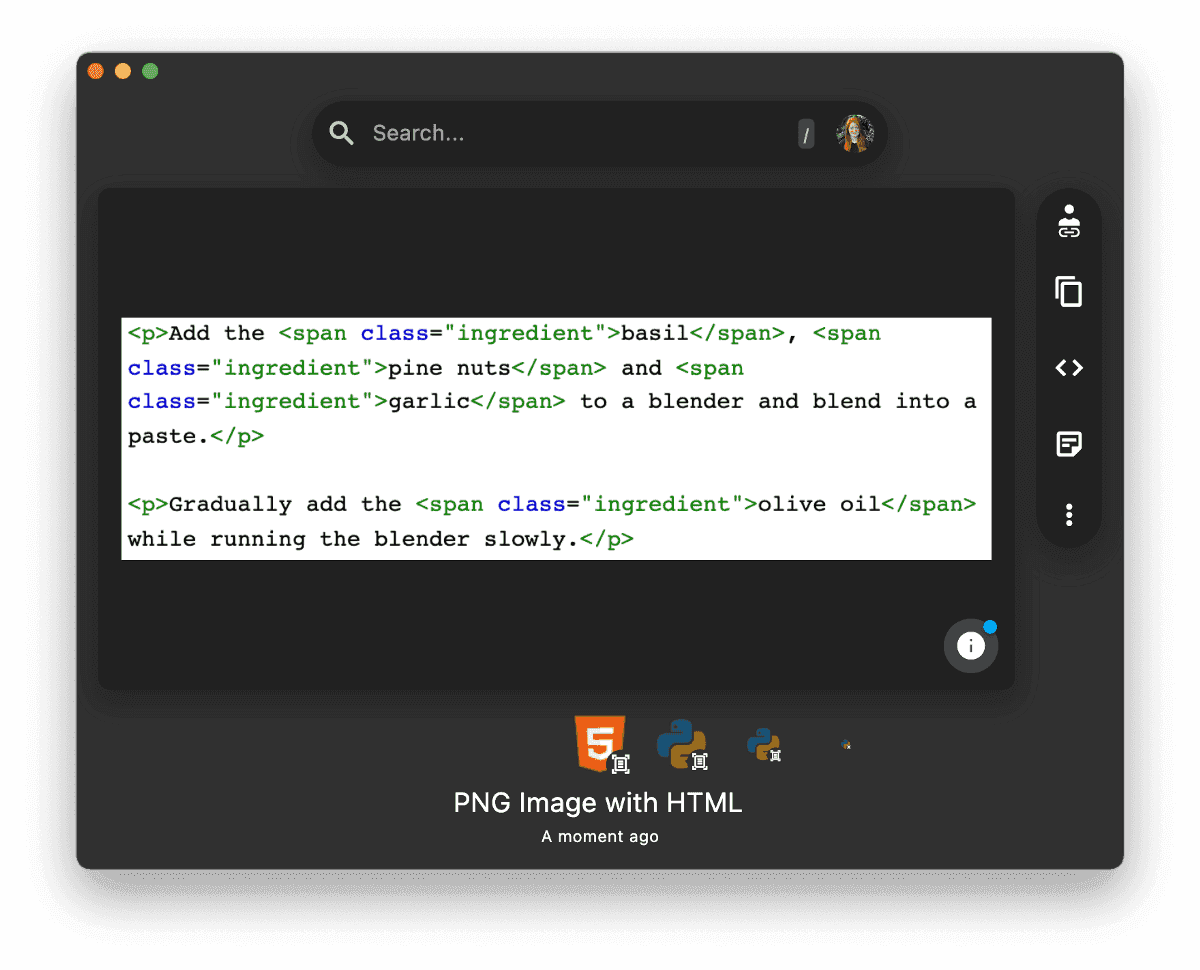
To determine which images are in dark mode, our engine first median-blurs the image to remove outliers and then calculates the average pixel brightness.
If it is lower than a specific threshold, it is determined to be dark and thus inverted.
To handle gradient and noisy backgrounds, we use a dilation-based approach.
We generate a copy of the image and apply a dilation kernel and median blur on it. We then subtract this blurred copy from the original image to remove dark areas without disturbing the text on the image.
For low-resolution images, we upsample the image depending on the input size using bicubic upsampling.
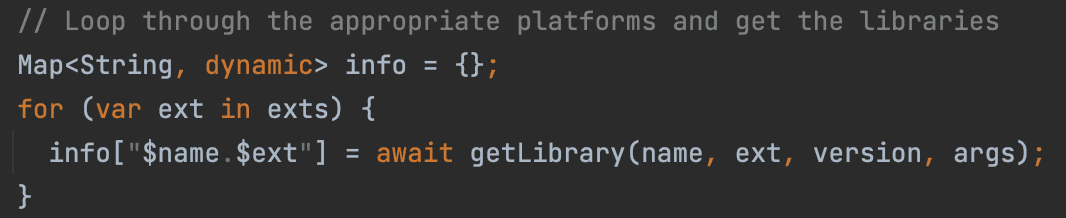
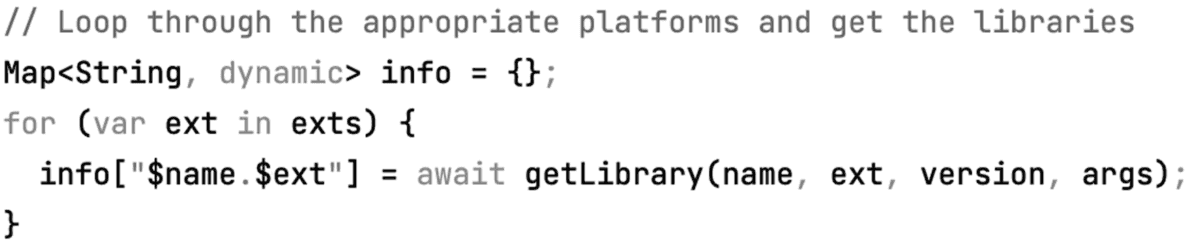
Code requires layout formatting
On the text prediction of Tesseract, we perform am OCR layout analysis and infer the indentation of the produced code.
Tesseract, by default, does not indent any output, which can not only make code less readable but even change its meaning in languages such as Python.
To add indentation, we use the bounding boxes that Tesseract returns for every line of code.
Using the width of the box and the number of characters found in it, we calculate the average width of a character in that line.
We then use the starting coordinates of the box to calculate by how many spaces is it indented compared to the other code lines.
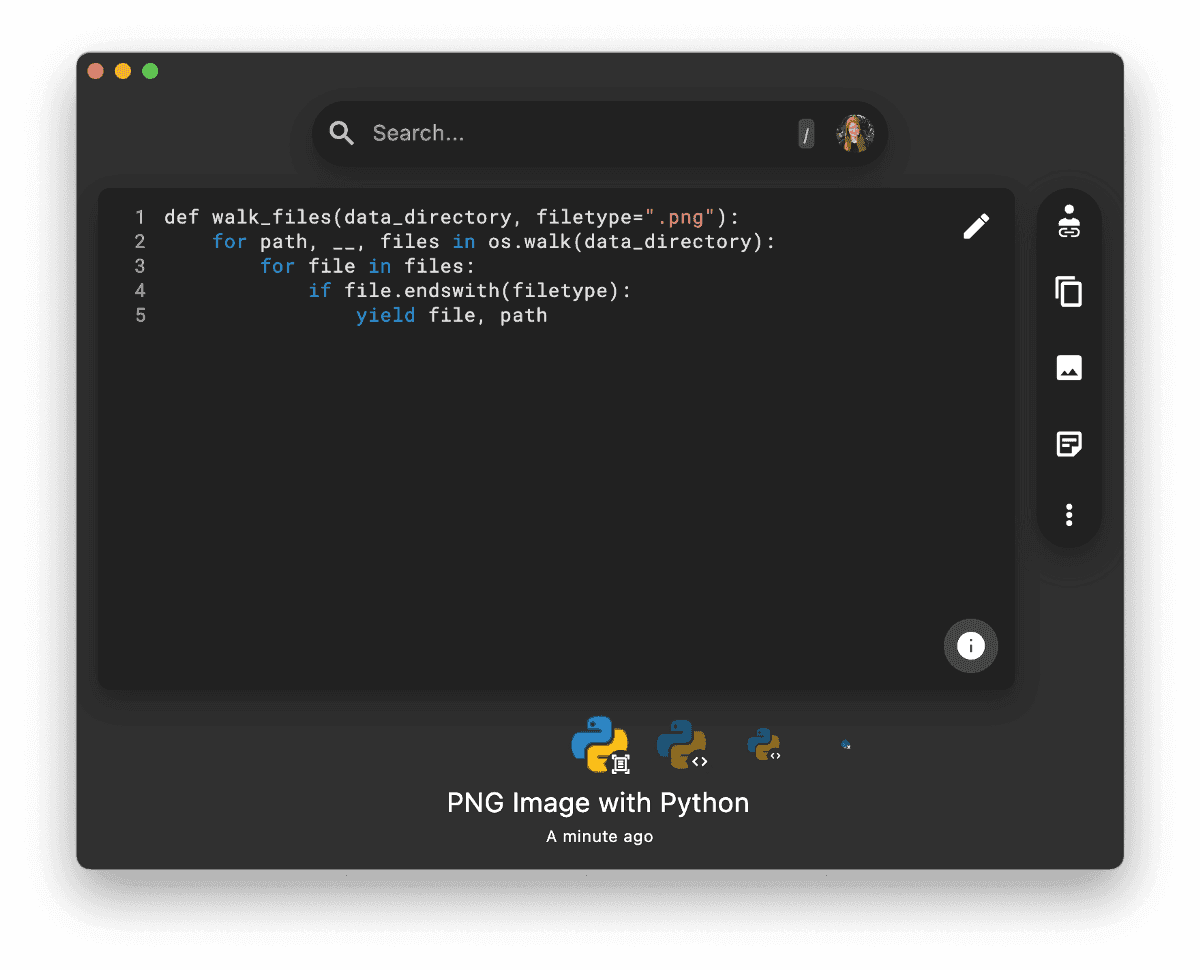
After that, we use a simple heuristic to push the indentations into even numbers of spaces.
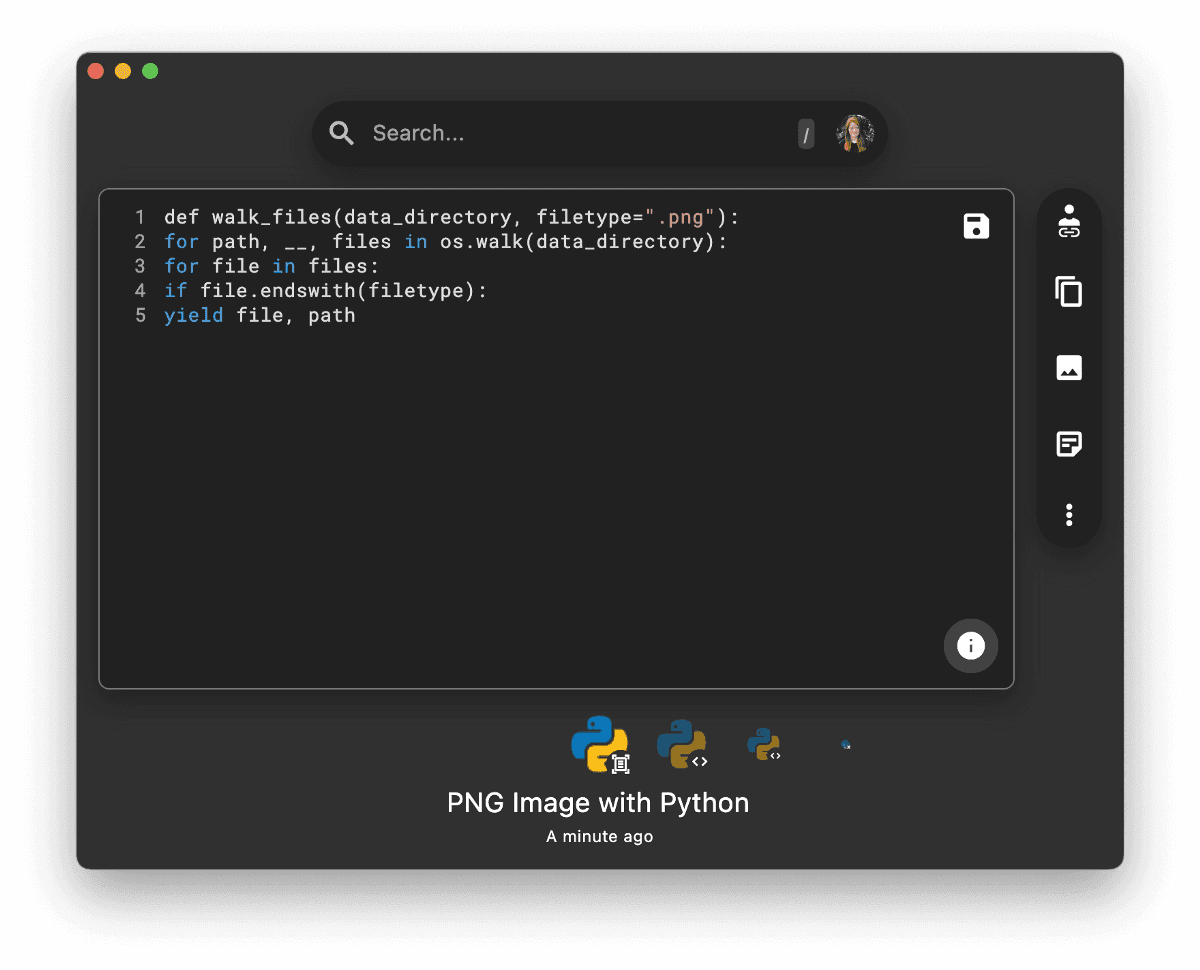
Evaluating our pipeline
To evaluate our modifications to the OCR pipeline, we use multiple sets of hand-crafted and generated datasets of image-text pairs.
By running OCR on each image, we then calculate the Levenshtein distance between the predicted text and the ground truth. We treat each modification as a research hypothesis and then use experiments to validate them.
For upsampling small images, for example, our research hypothesis was that super-resolution models like SRCNN (Super-Resolution Convolutional Neural Network) would boost OCR performance more than standard upsampling methods like nearest-neighbor interpolation or bicubic interpolation.
To test this hypothesis, we ran the OCR pipeline multiple times on the same datasets, each time using a different upsampling method.
While we found that nearest-neighbor upsampled images yield worse results, we did not find a significant difference between super-resolution-based upsampling and bicubic upsampling for our pipeline.
Given that super-resolution models need more storage space and have a higher latency than bicubic upsampling, we decided to go with bicubic upsampling for our pipeline.

Overall, getting OCR code right is a challenging objective, since it has to capture highly structured syntax and formatting while allowing for unstructured variable names and code comments.
We’re happy to provide one of the first OCR models fine-tuned to code and are continuing to improve the model to make it faster and more accurate, so you can get usable code from your screenshots and continue coding.
To test our model on your own code screenshots, download the Pieces desktop app.
If you’re a developer interested in our APIs, email us at support@pieces.app.
If you liked this article, you might want to read these ones written by me and some of my peers: